This article explains how improve the query performance of ASO cubes by building custom aggregate views and provides a way of manually generating the aggregate view ID’s and view file.
Building aggregate views is a two-step process:
-
Aggregate Selection -> selection of the aggregate views to be built
Selecting aggregate views can be done in two ways: - “execute aggregate selection” maxl command which select the “best” aggregate views by analysing the cube data together with outline hints and captured user queries. MaxL statement “execute aggregate process” does the same thing as the aggregate selection only with fewer options.
- or if you know your dimensions, your data and the user queries you can build the aggregate views manually and save them to file. This article will focus on this task.
For big databases already having an aggregate selection and not executing it every time saves a lot of time and allows for reduced maintenance windows.
- Aggregate view selection is single threaded while aggregate build is multi-threaded. This means that aggregate build can benefit from more cpu’s (Exalytics) while aggregate selection does not.
- Aggregate Build -> based on the selection step it builds/materialises aggregate views.
It receives as inputs either a set of aggregate view id’s or a file with aggregate views.
Performance of this step is mostly dependent on CALCPARALLEL settings, hardware, temp/default tablespace settings (cube outline and data of course).
The aggregate build process can benefit from multiple CPU’s for the most part. Some parts of the aggregate build like the commit from the Temp tablespace to the Default tablespace are single threaded which is not great
- for small databases it’s perfect. Sometimes aggregate views are not even needed.
- The default sample size to determine and estimate the size of aggregate views is 1,000,000 cells. This is fine for small cubes but needs to be adjusted for larger cubes using the Essbase CFG setting ASOSAMPLESIZEPERCENT. Increasing the value of this setting means more data will be analysed when determining what aggregate views meet selection criteria consequently the view selection and the size estimate is better.
- for bigger databases with big data and big dimensionality the selection is not as good. Not as good can quickly become unusable. Essbase cannot possibly know what queries will be running. For example it cannot know that the Period dimension will be always/mostly be used as level 0 so aggregate views might select upper level on Period which makes those views useless (this is just an example as you can use Dynamic dimensions or outline hints).
- It can take a long time (1-2 hrs) on big databases with big sample size (even when using an Exalytics box) and does not necessary provide the best aggregate views.
- Allows the selection of ‘better’ aggregate views. Always a good idea.
- When a cube first goes live there is no user query data. The cube needs to be usable for the users to start generating query data. Some people have implemented scripts that execute MDX queries or do Essbase retrieves so that when the Aggregate Selection process runs Essbase will identify specific views. This works but it would be a lot easier the actually specify what views you want to aggregate.
- Allow the selection of those aggregate views which are specifically meant to maximise query performance and get the best possible user experience
- Understating the dimensions, data, user queries and how user queries are affected by aggregate views is needed. This probably requires more in-depth knowledge and more development time then the automatic aggregate selection however the results can be from unusable cube to sub second reporting (or not, depends on the developer).
- Changes in dimension levels invalidate the aggregate views so they need to be recalculated. This process can be automated if needed.
- Get the outline ID of the cube
Run Maxl command “execute aggregate selection on database ASOsamp.Sample selecting 1 views force_dump to view_file 'VF_FILE1';”
The outline for ASOSamp ID is “4142187940”.
- Get dimension levels of the cube
Run Maxl command “query database ASOsamp.Sample list aso_level_info;”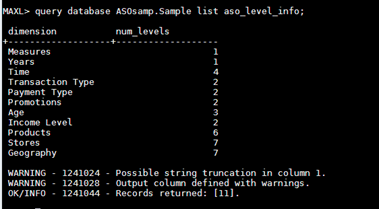
- Go to http://aggregateviewbuilder.azurewebsites.net and input the outline id and dimensions levels.
The inputs have been already set to use example ASOSamp application that ships with Hyperion however they can be changed to any database.
- Build custom Aggregate View Input the aggregate view in the right side of the screen as follows:
- An aggregate view is list of levels and each level corresponds to a dimension in the outline.
- One line represents an aggregate view
- Each view is made up of comma separated levels. These levels will identify a specific slice in the database that will be aggregated.
- Levels start from 0 and to a maximum of (Dimenion levels -1). So if the Time dimension has 4 levels then the aggregate view level can only have 0,1,2 or 3.
- The image below shows all dimensions and levels in the ASOSamp applications and 5 aggregate views:
- Generate aggregate view file and place it on the Essbase server in the ASOsamp.Sample folder.
Press the “Generate Aggregate View File” and copy the contents of the bottom text box to a file called “VF_FILE1.csc”.
Copy this file to the database folder (X:\Oracle\Middleware\user_projects\epmsystem1\EssbaseServer\essbaseserver1\app\ASOsamp\Sample).

- Run aggregate build
MaxL to run aggregate build:
execute aggregate build on database ASOsamp.Sample using view_file 'VF_FILE1';
- Check the size of the aggregate views and the performance of the cube.
Maxl to check aggregates:
set column_width 50;
query database ASOsamp.Sample list existing_views;

